「枝刈り」の思考で AI ワークフローを最適化する
これは計算機科学でいう枝刈りだ。
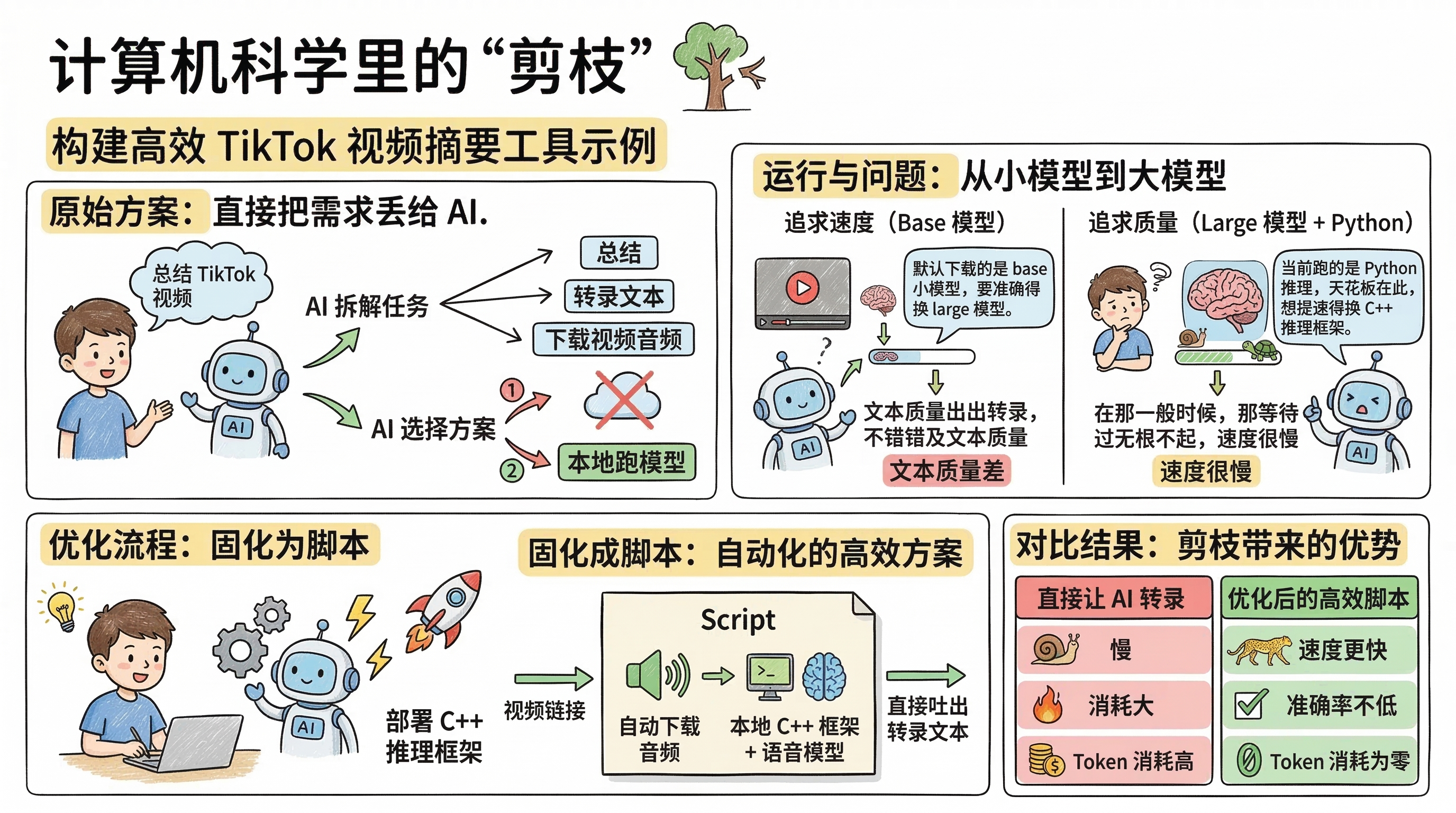
具体例を挙げよう。TikTok 動画の要約ツールを作りたいとする。
第1段階:AI にタスクを分解させる
要件をそのまま AI に投げると、AI は自分でタスクを分解する。動画を要約するにはまずテキストが必要で、テキストを得るには動画音声をダウンロードして書き起こしを行う必要がある。
ここまで来ると、AI は次の2案を出してくる。
- 音声をダウンロードした後、そのままクラウドモデルに渡して書き起こしする。
- 音声をダウンロードした後、ローカルでモデルを動かして書き起こしする。
AI は案2を選んだ。自動でローカルに音声文字起こしモデルをダウンロードし、さらに API で TikTok 音声を取得して、書き起こしを完了させた。
第2段階:問題を見つけ、段階的に最適化する
回線速度が十分なら全体の処理はスムーズだが、出力されたテキスト品質がかなり粗いことに気づく。
あなたが聞く。「なぜ結果がこんなにひどいんだ?」
AI:「デフォルトで base モデル をダウンロードしているからです。精度を上げるには large モデル に切り替える必要があります。」
large モデルをダウンロードして再実行すると品質は上がったが、今度は速度がかなり遅くなる。
あなたが聞く。「こんなに性能のいいマシンなのに、なぜまだ遅い?」
AI:「現在は Python 推論 で実行しています。ここが上限です。高速化したいなら C++ 推論フレームワーク へ切り替える必要があります。」
AI の指示どおりに C++ 推論フレームワークを再構築すると、ようやく速度が一気に上がった。
第3段階:フローを固定化する
最後に、処理全体をスクリプト化した。動画リンクを1つ渡すだけで、音声を自動ダウンロードし、ローカルの C++ 推論フレームワーク + 音声モデルを自動実行して、そのまま書き起こしテキストを出力する。
枝刈りの価値
ここで、これを「AI に直接書き起こしさせる」方法と比べてみる。
| 方式 | 速度 | 精度 | トークン消費 |
|---|---|---|---|
| AI に直接書き起こしさせる | 遅い | モデル依存 | 高い |
| ローカル C++ 推論 + 音声モデル | 速い | AI と同等以上 | ゼロ |
AI を直接使うと遅くて消費も大きい一方、2つ目のフローをスクリプト化すると、より速く、精度も低くならず、トークン消費はゼロになる。
枝刈りの本質は、AI が苦手な工程やコストの高い工程を、より適したツールで置き換えることだ。そして本当に知的判断が必要な工程でだけ AI を呼び出す。これは以前に述べた「なぜ人によって作る Skill の差が大きいのか」と同じ理屈で、まず技術方式を調査し、その後に AI を動かすべきだという話につながる。