Agent四要素の分解
タイムラインを見ていたら、Doubao、Qwen、Claude を Agent(エージェント)と呼んでいる人がいて驚いた。
Agentとは何か。以前の投稿でも触れたが、LLM(頭脳)+ Memory(長期/短期記憶)+ Planner(計画)+ Tool Use(ツール呼び出し)= AI Agent である。
この定義を満たしていれば、それはAgentだ。
Xで最もよく見かけるCode Agentは、Claude Codeと最近人気のOpenCodeである。
Xで最も話題の中国発Agentプロダクトは、Manus と Youmind だ。
では、この定義の構成要素を分解してみよう。
LLM
LLMは大規模モデルであり、すべての中核だ。私たちがよく言うClaude、Gemini、ChatGPT、Qwenはすべてモデルで、モデルがあるからこそ知能的な能力が生まれ、コードやドキュメントを出力できる。
ただし覚えておいてほしいのは、LLMは「出力するだけ」だということだ。自分では何も実行できない。だから大規模モデルの最初の形は ChatBot、つまり質問に答えるだけのチャットボットになる。
Memory
最も基礎的なMemoryはコンテキストで、どの大規模モデルにも最初から備わっている。現在は多くのモデルが 200Kコンテキスト で、1000K コンテキストまで到達したのはGeminiだけだ。
コンテキストは短期記憶なので、セッションを閉じると消える。ただ、長期記憶を実現する方法はいくつもあり、最もよく見かけるのが Claude.md だ。ファイルという形でコンテキスト情報を記憶させる。
ほかにも、ベクトルデータベースやグラフデータベースなどの方式があり、この領域を扱うOSSプロジェクトもX上に多い。
要するに、Memoryは大規模モデルにあなたとの対話履歴を覚えさせるための仕組みだ。
Planner
計画能力も、完全にモデル能力に依存する。さらにプロンプトへの依存も大きい。どのモデルにも一定の計画能力はあるが、平たく言えばモデルが推論を始めるということだ。強いモデルほど段階的に推論し、各ステップの完了後にいったん見直してから次へ進む。
計画の重要性は、タスク分解にある。大きなタスクを小さなタスクへ分け、順に処理できる。例えばWebページを作るなら、「React/Vueフレームワークの初期化」と「対応するHTML+CSSの埋め込み」という2つのタスクに分解できる。
Tool Use
ツール呼び出し能力は、大規模モデルがAgentになるための重要な能力だ。先に述べたように、大規模モデルはテキスト出力しかできない。だがツールを与えると、そのツールを駆動して操作できるようになる。
ここではClaude Codeの例を挙げる。コードを書くためのAgentとして登場したClaude Codeの内蔵ツール一覧は、次の図のとおりだ。
昨年、Claude Codeが公開された直後は、内蔵ツールはすべて Shell だった。主なツールはファイルの読み書きとテキスト検索である。
この数個のツール呼び出しだけで、Claude Codeは当時もっともコードベース探索が得意なAgentになった。代償として、トークン消費は爆発的に増えた。
Claude Codeにタスク処理を任せると、ツールを大量に呼び出しているのが分かる。特に読み書きツールは顕著で、1000行のファイルでも毎回200行ずつ読んでループする。
デバッグを頼むと、最初に呼ぶのは検索ツールだ。これらはすべてShellツールである。
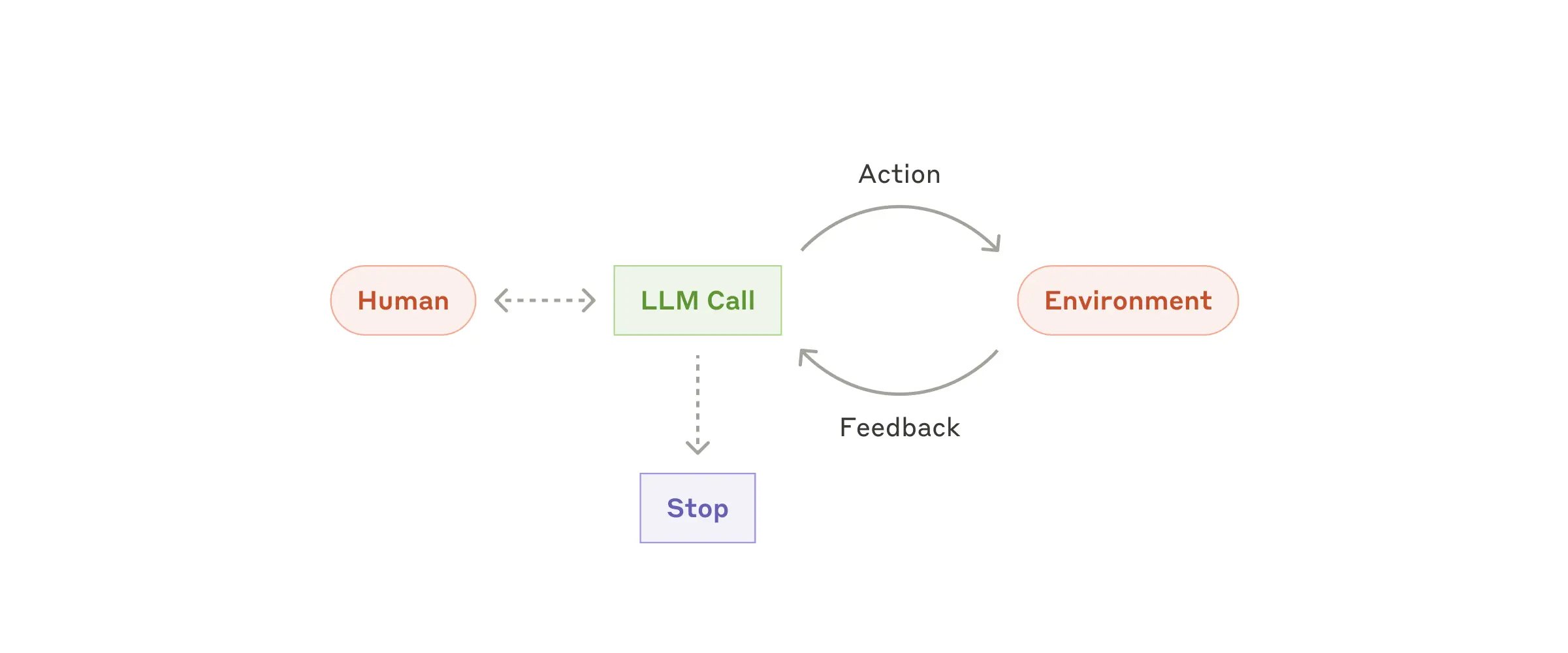
ReAct
ここまでを踏まえると、AI IDEは多数ある。Claude Code、Cursor、Trae、Google AntigravityはいずれもClaudeモデルを使えるのに、結果には大きな差が出る。例えばTraeは、Claude Codeを直接使うほどの効果は出ないと感じる人が多い。
理由は、Agentが上記4要素を柔軟にオーケストレーションする必要があるからだ。AgentはLLMを使ってコード生成結果を評価し、タスク分解に問題がないかを見て、ツール呼び出しでエラーが出たときの対処まで行わなければならない。
この文脈で生まれたのがAgentの設計パターンで、最も基礎的なのが ReAct だ。中核は反復するループで、通常は次の手順を含む。
- Thought(思考):モデルが現在のタスクを分析し、次に何をするか決める。
- Action(行動):モデルがどのツール(Google検索、Read、Writeなど)を呼ぶか、そしてどのパラメータを渡すかを決める。
- Observation(観察):ここでモデルは一時停止し、外部環境(コード/API)がツールを実行するのを待つ。実行結果はテキストとしてモデルに返される。
- Repeat(反復):モデルはObservationの結果に基づいて、新しいThoughtを開始する。
このループ設計が甘いと、モデルが見せる能力に雲泥の差が出る。OpenCodeが最近これほど注目される理由もここにあり、従来のAgentを拡張して、複数モデルの得意能力を組み合わせてAgentにオーケストレーションさせている。
Agentプロダクト
最後に、Agentプロダクトについて触れる。まず、現在のCode IDEはすべてAgentプロダクトだ。なぜなら上記能力を備え、さらにコード作成向けのプロンプトとコンテキスト設計まで作り込んでいるからである。Cursorが出始めた頃、効果が高かったために多くの人がプロンプトをリバースしていたのを覚えている。
Agentの重点を調整すると、プロダクトの性格が変わる。例えばManusだ。
Manusは検索統合が得意で、内部フィルタインターフェースを通じて多くのデータを探し、最後に要約をまとめて返せる。小红书向けのデータが欲しければ新榜で探し、時事データが欲しければニュースサイトで探す。さらに長時間連続で走り続けてタスクを完了できる(上で触れたLoop)。
これらはすべて、創業者が自社プロダクトの位置づけに合わせてAgentの重点を再構築した結果だ。そこにはAgent設計だけでなく、プロンプト最適化も含まれる。
例えばYoumindはプロンプト最適化を深く行っているため、同じプロンプトでもYoumindでの画像生成のほうが良いという声が多い。基盤モデルはいずれもNano Bananaモデルである。
ここにはツール面の差もある。同じ調査質問でも、Doubaoに聞くとGoogle検索を実行できないので、要約の多くが中身の薄いものになりやすい。
しかしGeminiならGoogle検索を使って全体を横断的に調べられる。こうした内部の高品質情報源こそ、Agentの堀(モート)になる。
最後に、冒頭の問いへ戻ろう。
モデルはモデル、AgentはAgentであり、両者を同一視してはいけない。